Andrew McKay, KonaSearch CEO, Excerpt from Webinar
Taking a deep dive into enterprise search in Salesforce
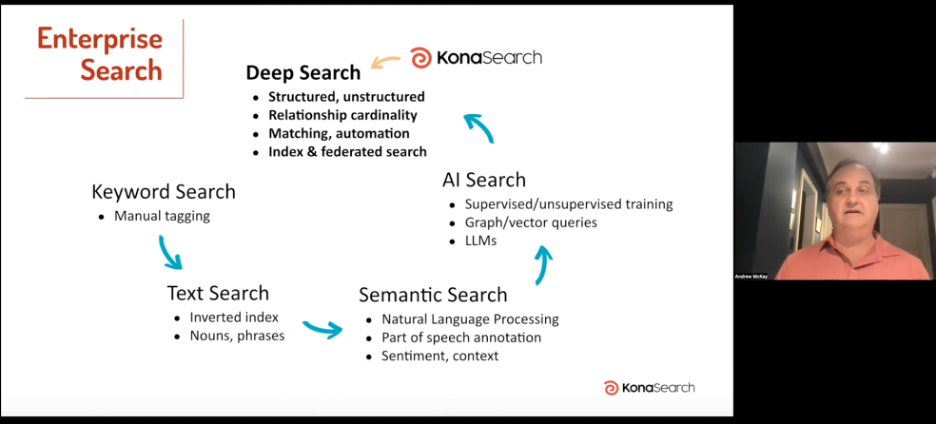
The search industry has been very interesting in the last number of decades. The old Fairbanks Center for Research still has meaning and only in the sense that it’s not a consumer search. If we think about the history, we started with keywords, ended up with text searches, and then introduced the inverted index. Then we moved into semantic types of searches with NLP and parts of speech etc.
Then we moved into AI search when we started to realize that graph queries and then vector queries along with LMS and general training were actually something that was useful. Then finally is what we call deep search, which is really bringing together all of the wonderful new capabilities that search has brought through its generations, but also taking a look at what SQL has been doing completely in parallel.
Combination of qualitative and quantitative search
Salesforce is a traditional relational database, unfortunately, is predominantly populated by text. And the reason that that’s actually an interesting trial by fire is that traditional databases are lots of numbers. Quantitative search and analysis have been around forever but when it comes to the combination of qualitative and quantitative search, that requires a different way of thinking because search has been very good at looking at blocks of text. Not so much at understanding the relationship and commonality.
KonaSearch has brought the two of them together in a way that allows you in the Salesforce community, for example, to search deeply through content as if it was semantically part of the records in Salesforce and vice versa.
Curate data in context within the workflow
We realized that search is less about search. Salesforce went to market not because it said, I have a great relational database construct in the cloud. They said, Hey, I’ve got a sales cloud product. I got a CRM. But what they really put out there was their platform. And it’s the same thing with search. These days, it’s less about search and more about what search provides. And what it provides is an ability to curate data in context within the workflow of a person’s day-to-day management of information. And to do so in a way that actually the search is really there almost in the background in a lights-out type of fashion.
And to give an idea of the application that we’re implementing today in terms of what KonaSearch does, they range from talent matching, which is being able to match job orders to candidates and candidates to job orders, ultimately to say, there’s a whole bag of job order descriptions. Here’s a whole bag of resumes, match them up. And then IP protection, a lights-out system that monitors data coming in from an organization and is able to find content that is inappropriate IP and lock it down.
Legal case monitoring, notify me when people add dockets to my case. I’m talking about federal cases and that thing. And find me more cases like this one. Investment monitoring, executive dashboards, border automation, brand targeting, service automation, and compliance monitoring. These are the types of new variations of applications that you’re building today where the foundation behind them is the search engine.
We understand the true essence of a search index. It’s basically just name-value pairs pointing to everything all over the place. The KonaSearch schema is the same schema for every one of our customers, even though every experience that they have is unique using KonaSearch. We did not want to screw around with ingestion models. And the only ingestion model that we have in there that’s permanent, there’s two of them, one for languages, because we have to support every language that Salesforce has. And we have a strong office in Tokyo where we have some significant Japanese clients. And the second one is to understand OCR. So we use Tesseract as our back end, and we’ve added our own capabilities into Tesseract, enhancing the clustering capabilities it provides. But in any event, the entire ingestion process and the schema is common across all of our components. It’s very, very abstract, but the reality is that when we index all that content, even though it presents a unique experience, the reality is that it all goes in a schema, and most of it is handling the commonality that is inherent across relationships in relational databases.
Sample queries
We built a demo. The hard part is trying to find data. So what we did here is we decided, why don’t we just index the New York Stock Exchange and then go out and grab all of their annual reports? So we did that. And in fact, we’re going to light it up as a portal that can be used for public access and updated points of the day and see if people are interested in the information.
Let’s say I have a query that says:
- I’m a private equity company and somebody comes to me and says, I want to invest in companies that are listed on the New York Stock Exchange and related exchanges
- They should be in the real estate, financial, health care, or IT sectors
- They have a market cap greater than $30 billion
- They have a share price lower than $200, and a PVE of at least 10
- They are committed to diversity in the workplace.
That’s the quality data segment!
So this is just a typical search page. It can look very different from client to client. It’s also in Salesforce. So those of you who are familiar with Salesforce, you might recognize the layout.
Results of the query:
- 164 results showing up here because I have these various sectors.
- If I clear out all my filters and I do a run, I’ll show 8,745 entries or listings.
- When I run that query, I end up with eight results.
Here you can see the quantitative components put in on a filter level, and the qualitative one is put into the search query, but it can be put in and devised in many different ways. In any event, that query has resulted in a set of SEC filings. You’ll notice here that we’re doing deep searches through the filings themselves, PDFs, some of them are OCR, and so on and so forth. And we also have the quantitative data in here as well, which actually sits in various different tables of the relationships.
For example, we want to find the CEO. The CEO happens to be a contact record as a child on the account records of the listening. But it gives you an idea of how deep we can go into these things. In any event here, you’ll see that we are just looking for every occurrence of employee diversity. We’re finding all the ones that are within five words of each other. Near operators, for anybody who’s used to the search industry, are very common. There are many other operators in our language. And in our particular environment, there are customers in recruiting who really like the idea of typing in brilliant queries. There are others who just want a point and click to get where they want. Then there are others who are actually very much interested in being able to take context from another object or another record and say, I want to open up the search page with a pre-run search based on the salient features or just a fuzzy profile of the record I’m in.